| employee_id | sales_total | manager_employee_id |
| 1 | 253 | NULL |
| 2 | 308 | 1 |
| 3 | 92 | 1 |
| 4 | 20 | 2 |
| 5 | 148 | 4 |
| 6 | 377 | 1 |
| 7 | 87 | 2 |
Unlocking hierarchical graph operations in pure Spark.
Graph databases naturally represent hierarchical data, complex relationships, and arbitrary attributes (e.g. key-value pairs). Are they the best option for datasets heavy with these features? Yes, as far as the data model goes. But, there are other considerations:
Although graph databases are often the better technology, relational databases have the home team advantage. In many enterprises, the value of graph databases can’t cover the immediate switching costs.
This creates the situation where graph-like data is shoehorned into relational databases. Migrating datasets to graph databases may be the ideal, but in the meantime…
Some tools, like NetworkX and GraphFrames, provide methods to construct graph abstractions from DataFrames. (See nx.from_pandas_edgelist and Creating GraphFrames.) This allows graph operations on top of familiar tabular structures. These solutions won’t outperform a true graph database, but they’re a reasonable stopgap. If you need algorithms like betweeness to identify supply chain risk or node similarity to resolve entities, these tools are great options.
On the other hand, your application may not need the horsepower these tools provide. If you’re running a lean deployment, it may hard to justify the additional dependency. Below, we’ll write a descendants method to demonstrate how basic graph operations can be implemented in pure PySpark.
Arbitrarily nested hierarchical data, like org structures or bills-of-materials, are commonly stored in relational databases. For example:
| employee_id | sales_total | manager_employee_id |
| 1 | 253 | NULL |
| 2 | 308 | 1 |
| 3 | 92 | 1 |
| 4 | 20 | 2 |
| 5 | 148 | 4 |
| 6 | 377 | 1 |
| 7 | 87 | 2 |
Visually:
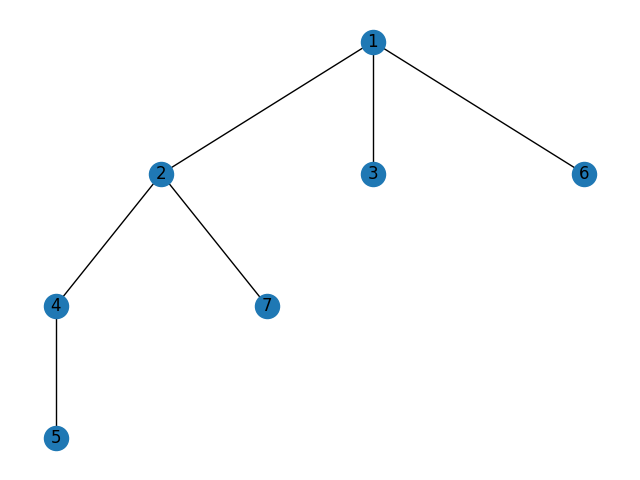
The goal is to the crawl this hierarchy to produce a list of all descendants of each node. Descendants of node 4 should be [5], of node 2 should be [4, 5, 7], and so on. The full target output is:
| employee_id | sales_total | manager_employee_id | descendants |
| 1 | 253 | NULL | [2, 3, 4, 5, 6, 7] |
| 2 | 308 | 1 | [4, 5, 7] |
| 3 | 92 | 1 | [] |
| 4 | 20 | 2 | [5] |
| 5 | 148 | 4 | [] |
| 6 | 377 | 1 | [] |
| 7 | 87 | 2 | [] |
To get a list of all descendants, we’ll first start with a list of descendants in the immediate next generation.
import pyspark.sql.functions as psf
direct_reports = (
df.alias("left")
.join(
df.alias("right"),
1 on=[psf.col(f"left.employee_id") == psf.col(f"right.manager_employee_id")],
how="left",
)
2 .groupby(*[f"left.{col}" for col in df.columns])
3 .agg(psf.collect_set("right.employee_id").alias("direct_report_employee_ids"))
)left to each of their direct reports in right.
The output:
| employee_id | sales_total | manager_employee_id | direct_report_employee_ids |
| 1 | 253 | NULL | [2, 6, 3] |
| 2 | 308 | 1 | [7, 4] |
| 3 | 92 | 1 | [] |
| 4 | 20 | 2 | [5] |
| 5 | 148 | 4 | [] |
| 6 | 377 | 1 | [] |
| 7 | 87 | 2 | [] |
Capturing descendants in the next-level of hierarchy:
deg2_direct_reports = (
direct_reports.alias("left")
.join(
direct_reports.alias("right"),
on=[
psf.array_contains(
"left.direct_report_employee_ids",
1 psf.col("right.manager_employee_id"),
)
],
how="left",
)
2 .groupby(*[f"left.{col}" for col in direct_reports.columns])
3 .agg(psf.collect_set("right.employee_id").alias("deg2_direct_report_employee_ids"))
)left to each of their direct reports in right.
The output:
| employee_id | sales_total | manager_employee_id | direct_report_employee_ids | deg2_direct_report_employee_ids |
| 1 | 253 | NULL | [2, 6, 3] | [7, 4] |
| 2 | 308 | 1 | [7, 4] | [5] |
| 3 | 92 | 1 | [] | [] |
| 4 | 20 | 2 | [5] | [] |
| 5 | 148 | 4 | [] | [] |
| 6 | 377 | 1 | [] | [] |
| 7 | 87 | 2 | [] | [] |
single_generation_descendantsWe’ll repeat this process to return all descendants, querying the next generation descendants of the prior generation descendants until the hierarchy terminates with no descendants remaining. Here’s a generalized implementation:
import pyspark.sql as ps
from typing import Optional
def single_generation_descendants(
df,
id_col_name: str, # id of the referent row
parent_id_col_name: str, # reference to the immediate parent
child_ids_col_name: Optional[str] = None, # reference to children in any particular generation
degree_num: Optional[int] = None, # avoids duplicate column names on chained calls
) -> ps.DataFrame:
# accounts for differences in join logic between the first and subsequent generations
assert (
"array" not in df.select(id_col_name).dtypes[0][-1]
), f"The ID column ({id_col_name}) cannot be an array."
assert (
"array" not in df.select(parent_id_col_name).dtypes[0][-1]
), f"The parent ID column ({parent_id_col_name}) cannot be an array."
if child_ids_col_name is None:
join_condition = psf.col(f"left.{id_col_name}") == psf.col(f"right.{parent_id_col_name}")
else:
assert (
"array" in df.select(child_ids_col_name).dtypes[0][-1]
), f"The child IDs column ({child_ids_col_name}) must be an array."
join_condition = psf.array_contains(
psf.col(f"left.{child_ids_col_name}"),
psf.col(f"right.{parent_id_col_name}"),
)
agg_func = psf.collect_set(psf.col(f"right.{id_col_name}"))
descendants_prefix = "next_gen_" if degree_num is None else f"deg{degree_num}_"
return (
df.alias("left")
.join(
df.alias("right").select(id_col_name, parent_id_col_name),
on=[join_condition],
how="left",
)
.groupby(*[psf.col(f"left.{col}") for col in df.columns])
.agg(agg_func.alias(f"{descendants_prefix}descendants"))
)Integer and integer join condition.
next_gen_descendants produces the expected result:
from pyspark.testing.utils import assertDataFrameEqual
assertDataFrameEqual(
single_generation_descendants(df, "employee_id", "manager_employee_id"),
direct_reports.withColumnRenamed("direct_report_employee_ids", "next_gen_descendants"),
)Array and integer join condition.
Chaining next_gen_descendants twice produces the expected result:
id_col_name = "employee_id"
parent_id_col_name = "manager_employee_id"
assertDataFrameEqual(
(
df.transform(
single_generation_descendants, id_col_name, parent_id_col_name, degree_num=1
).transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
"deg1_descendants",
2,
)
),
deg2_direct_reports.withColumnsRenamed(
{
"direct_report_employee_ids": "deg1_descendants",
"deg2_direct_report_employee_ids": "deg2_descendants",
}
),
)descendantsRecursive algorithms require two fundamental elements:
While the final descendants function won’t truly be recursive (it won’t call itself), it will have both accumulation logic and an end condition.
Focusing on the end condition, we see next_gen_descendants returns no descendants on the fourth call:
(
df.transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
degree_num=1,
)
.transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
"deg1_descendants",
degree_num=2,
)
.transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
"deg2_descendants",
degree_num=3,
)
.transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
"deg3_descendants",
degree_num=4,
)
)| employee_id | sales_total | manager_employee_id | deg1_descendants | deg2_descendants | deg3_descendants | deg4_descendants |
| 1 | 253 | NULL | [2, 6, 3] | [7, 4] | [5] | [] |
| 2 | 308 | 1 | [7, 4] | [5] | [] | [] |
| 3 | 92 | 1 | [] | [] | [] | [] |
| 4 | 20 | 2 | [5] | [] | [] | [] |
| 5 | 148 | 4 | [] | [] | [] | [] |
| 6 | 377 | 1 | [] | [] | [] | [] |
| 7 | 87 | 2 | [] | [] | [] | [] |
So, we’re one generation beyond the end state when WHERE size({last_crawled_gen_descendants}) > 0 returns no data.
(
df.transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
degree_num=1,
)
.transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
"deg1_descendants",
degree_num=2,
)
.transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
"deg2_descendants",
degree_num=3,
)
.transform(
single_generation_descendants,
id_col_name,
parent_id_col_name,
"deg3_descendants",
degree_num=4,
)
).filter(psf.size("deg4_descendants") > 0).rdd.isEmpty()TrueWrapping this together:
def descendants(
df: ps.DataFrame,
id_col_name: str, # column name of the ID column that identifies the node
parent_id_col_name: str, # column of the parent ID column that identifies the parent node
) -> ps.DataFrame:
def _next_gen_exists(
maybe_next_gen_descendants: ps.DataFrame,
) -> bool:
return not maybe_next_gen_descendants.filter(
psf.size(maybe_next_gen_descendants.columns[-1]) > 0
).rdd.isEmpty()
# get next generation descendants
# next_gen_descendants accumulates by appending to the returned DataFrame
1 degree_num = 1
2 maybe_next_gen_descendants = single_generation_descendants(
df, id_col_name, parent_id_col_name, degree_num=degree_num
)
# if at least one descendant exists in the next generation,
# update table of all descendants and check the next generation
3 while _next_gen_exists(maybe_next_gen_descendants):
wide_descendants = maybe_next_gen_descendants
4 degree_num += 1
5 maybe_next_gen_descendants = single_generation_descendants(
wide_descendants,
id_col_name,
parent_id_col_name,
maybe_next_gen_descendants.columns[-1],
degree_num=degree_num,
)
# merge descendants into one list
descendant_col_names = [
col for col in wide_descendants.columns if col not in df.columns
]
# return wide_descendants
7 return wide_descendants.withColumn(
"descendants",
psf.array_sort(psf.flatten(psf.array(*descendant_col_names))),
).drop(*descendant_col_names)degree_num = 1
degree_num
descendants(df, "employee_id", "manager_employee_id")| employee_id | sales_total | manager_employee_id | descendants |
| 1 | 253 | NULL | [2, 3, 4, 5, 6, 7] |
| 2 | 308 | 1 | [4, 5, 7] |
| 3 | 92 | 1 | [] |
| 4 | 20 | 2 | [5] |
| 5 | 148 | 4 | [] |
| 6 | 377 | 1 | [] |
| 7 | 87 | 2 | [] |
Verifying:
assertDataFrameEqual(descendants(df, "employee_id", "manager_employee_id"), target_df)All good.
With a full list of descendants for each record, it’s trivial run aggregations over the rolled up hierarchy.
descendant_df = descendants(df, "employee_id", "manager_employee_id")
descendant_df.alias("left").join(
descendant_df.alias("right").select("employee_id", "sales_total"),
on=[
(psf.col("left.employee_id") == psf.col("right.employee_id"))
| (
psf.array_contains(
psf.col("left.descendants"),
psf.col("right.employee_id"),
)
)
],
).groupby([psf.col(f"left.{col}") for col in descendant_df.columns]).agg(
psf.sum("right.sales_total").alias("rollup_sales_total")
)| employee_id | sales_total | manager_employee_id | descendants | rollup_sales_total |
| 1 | 253 | NULL | [2, 3, 4, 5, 6, 7] | 1285 |
| 2 | 308 | 1 | [4, 5, 7] | 563 |
| 3 | 92 | 1 | [] | 92 |
| 4 | 20 | 2 | [5] | 168 |
| 5 | 148 | 4 | [] | 148 |
| 6 | 377 | 1 | [] | 377 |
| 7 | 87 | 2 | [] | 87 |
def hierarchical_rollup(
df: ps.DataFrame, id_col_name: str, parent_id_col_name: str
) -> ps.GroupedData:
descendant_df = descendants(df, id_col_name, parent_id_col_name)
rolled_up_data = (
descendant_df.withColumnsRenamed(
{col: f"_left_{col}" for col in descendant_df.columns if col != id_col_name}
)
.join(
descendant_df.withColumnsRenamed({id_col_name: f"_right_{id_col_name}"}),
on=[
(psf.col(id_col_name) == psf.col(f"_right_{id_col_name}"))
| (
psf.array_contains(
psf.col("_left_descendants"),
psf.col(f"_right_{id_col_name}"),
)
)
],
)
.groupby(id_col_name)
)
return rolled_up_datadf.join(
hierarchical_rollup(df, "employee_id", "manager_employee_id").agg(
psf.sum("sales_total").alias("rollup_sales_total")
),
"employee_id",
)| employee_id | sales_total | manager_employee_id | rollup_sales_total |
| 1 | 253 | NULL | 1285 |
| 2 | 308 | 1 | 563 |
| 3 | 92 | 1 | 92 |
| 4 | 20 | 2 | 168 |
| 5 | 148 | 4 | 148 |
| 6 | 377 | 1 | 377 |
| 7 | 87 | 2 | 87 |
In some cases, implementing your own graph algorithms in your team’s SQL engine may be the best option. Above, we covered implementing descendants using the PySpark DataFrame API by using self-joins and built-in array operations. Similar techniques could be used to look up ancestors, degree, etc.